
Introduction
With the rapid development and rise of artificial intelligence, deep learning is widely adopted in daily life. This leads to many companies to pay more attention to the rapid allocation of computing resources and rapid training of models when building deep learning models, so as to improve their own resource utilization and training quality. At present, the hurdle for using TensorFlow is relatively high, especially for distributed TensorFlow computing. The complicated configuration has brought great challenges to traditional IT staffs.
Kubernetes is a distributed cloud platform architecture based on container technology. It is one of the most popular Platform-as-a-Service (PaaS) platforms and supports the most popular Docker technology. Kubernetes has the advantages of automatic resource management, maximized resource utilization, and microservice architecture. Compared with traditional virtualization technologies, it has higher performance, faster speed, and lower cost.
TensorFlow is an excellent deep learning framework, and the distributed computing of heterogeneous devices is one of its highlights. TensorFlow supports convolutional neural networks, recurrent features such as neural network, Docker operation, automatic differentiation and most algorithm libraries. This article aims at the current large-scale use of distributed TensorFlow in enterprises.
It is impossible to realize the rapid allocation of underlying resources, simplify the complex TensorFlow configuration, and quickly build the model. A solution is proposed to containerize TensorFlow and run it on the Kubernetes PaaS cloud platform. This article also introduces the design and implementation of the distributed TensorFlow platform based on Kubernetes. Through this platform, the rapid construction of the distributed TensorFlow environment, the unified allocation of limited physical resources, and the second-level deployment of TensorFlow containers have greatly improved the efficiency of model development. It reduces the threshold for using distributed Tensor-Flow, completely isolates the interaction between platform users and the underlying environment, and finally realizes the rapid construction of models, efficient training of models, and one-click deployment of models.
Architecture Design
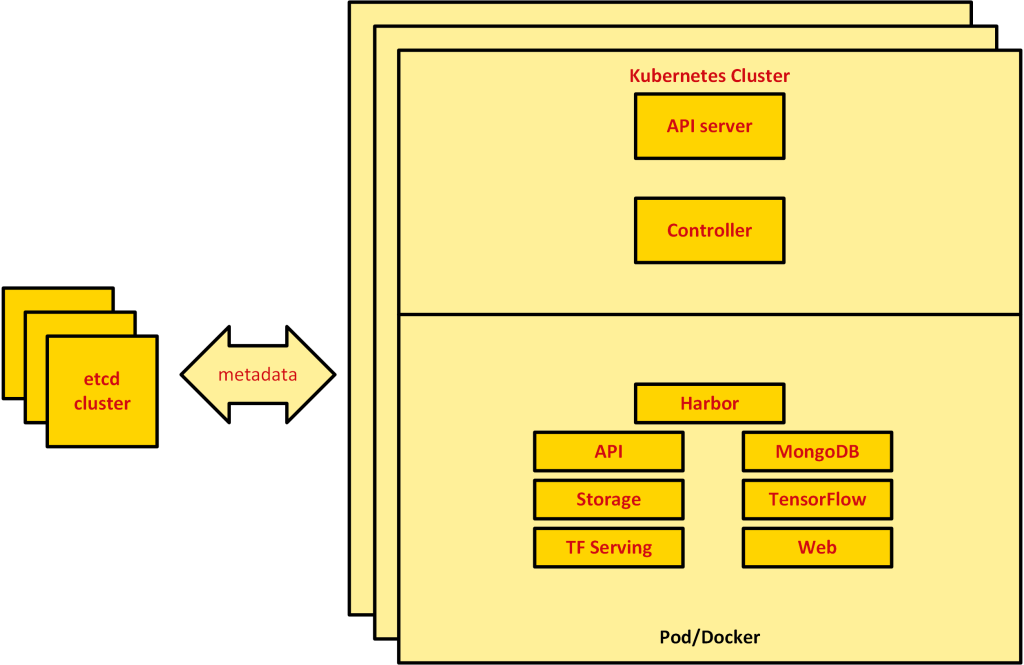
The overall architecture design of the distributed deep learning platform system based on Kubernetes is shown in below:

The system as a whole is divided into physical resource IaaS layer, Kubernetes PaaS layer, application layer and user layer.
Physical resources The IaaS layer is mainly the underlying machine resources, including physical machines, virtual machines, and cloud hosts. Usually, enterprises will have their own IaaS layer, and the current mainstream IaaS layer platforms include Openstack, VMware, etc. The Kubernetes PaaS layer is mainly a PaaS cloud platform built by Kubernetes, and the PaaS platform will control all applications in the application layer, such as the container registry (harbor), API (distributed TensorFlow platform service), TensorFlow, MongoDB, TensorFlow deep learning platform Web front-end and other applications will be containerized and deployed on the PaaS platform, application life cycle, resource allocation, etc. All are controlled and managed by the platform.
The application layer is mainly the application program of the deployment platform. Of course, other applications not related to the deep learning platform can also be deployed. As long as the application has been containerized and uploaded (Push) to the container registry, it can be deployed on the PaaS platform.
The user control layer is mainly to control the user’s authority, providing a unified
Log in to the registration service, and users only need to verify once when using the entire platform to use all services of the PaaS platform, including API, a service of the distributed TensorFlow deep learning platform. The API is a core service of this article. It mainly provides external services such as creating and deleting TensorFlow containers, training logs, TensorBoard, TensorFlow Serving, and TensorFlow task details. The created TensorFlow task types include parameter server (PS) and worker nodes.
In order to ensure the high availability of the Kubernetes cluster, the etcd cluster is adopted. etcd is a high-performance storage system based on key-value pairs. Since Kubernetes will store all metadata information in etcd, if the single-node etcd It cannot meet the main and backup requirements. The use of etcd clusters can effectively prevent the impact of etcd downtime. API-Server is the core component of calling Kubernetes API, which is very important to API, because it will call API-Server in Kubernetes to create services such as TensorFlow, TensorBoard, Tensor. The distributed container registry is also deployed on the Kubernetes platform, and Kubernetes is the control center of the entire platform.
Kubernetes Architecture
In this article, Kubernetes 1.7 will be adopted, and builds two Kubernetes clusters, and runs a large number of containers on the Kubernetes platform, as shown in below:
The Kubernetes architecture diagram is shown in below, where Pod is its basic operating unit, and each Pod can contain multiple Docker containers, which share resources, but in this paper, each Pod will only run one Docker.
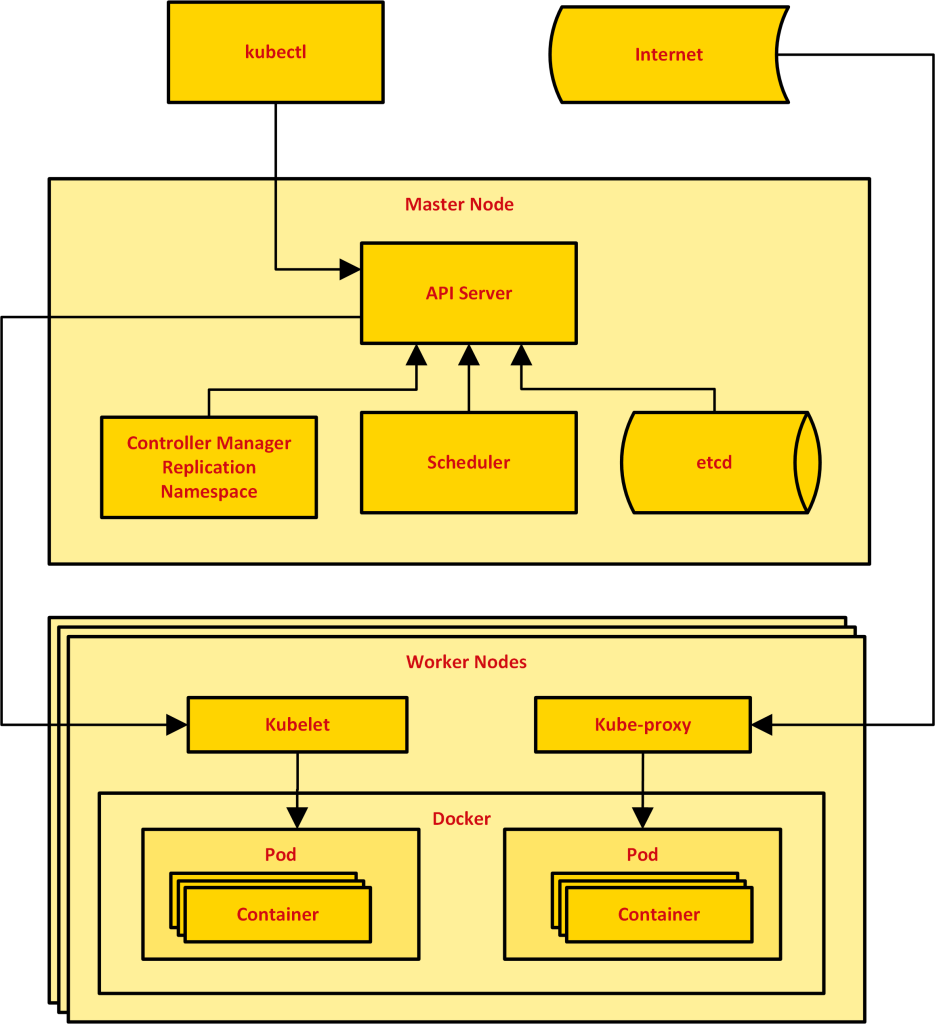
Job is a resource object of Kubernetes. It is mainly used to control batch tasks. Using Job can ensure that the Pod is always in the running state. If it encounters a failure in the middle, it will restart itself to ensure the Running state of the Pod.
DaemonSet can guarantee that in the work section of each Kubernetes machine
At least one Pod of this type of task should be running on the point, and the running node can also specify a specific machine node through label, that is, nodeSelector, so as to ensure that some core services are running on specific nodes.
PetSet was renamed StatefulSet after Kubernetes1.5, mainly to provide some stateful services, because the aforementioned ReplicationController and ReplicaSets are stateless, and the names of these Pods are randomly generated by Kubernetes , the Pod will change every time it is restarted, and this kind of Pod generally does not mount the storage system. It can be said that StatefulSet is designed for stateful services. The Pod started by StatefulSet will keep the same name, no matter how many times the Pod is restarted, it will not change. This feature can better ensure the continuity of service status, thereby improving High availability of services.
Federation is an important feature of Kubernetes cross-cluster, which is called cluster federation in Chinese. Usually, hosts are distributed in different regions, different availability zones, different cloud service providers, or some local machines. Kubernetes is also gradually improving this feature, and cross-cluster requires a good network, so as to meet the rapid allocation and scheduling of Kubernetes, so as to meet the needs of storage and computing performance. At present, Kubernetes also provides a dedicated API for Federation, and many companies are boldly trying this feature. The two Kubernetes clusters constructed in this paper are both on the same network segment, and the feature of Federation is not used.
The API is the only channel for users to interact with TensorFlow. Platform users submit corresponding task details through the platform portal Web front-end. The API will call the API-Server in Kubernetes according to the information provided by users, and integrate the entire creation process and The data information is stored in MongoDB, and the task information is returned to the user in real time. The call diagram is shown in below.
Overall Design of API Functional Modules
The detailed process is as follows: API will be containerized and deployed to the Kubernetes PaaS platform. It will call the API-Server of Kubernetes when creating or deleting TensorFlow tasks; The API will provide the creation/deletion of distributed TensorFlow, obtain the list of all distributed TensorFlow of a specified user and the detailed information of a certain distributed TensorFlow; log information, etc.
Design and Development of the API
At present, in the field of software development, the mainstream API development conforms to the Restful specification, and the development of all APIs are also in the Restful style. The development language of the entire platform is Golang. Golang is an excellent open source programming language of Google. Its super high concurrency is one of its highlights. It is currently widely used in the fields of cloud computing and big data. The development languages of Docker and Kubernetes are also All are implemented by Golang. Using Golang can also better combine the API distributed deep learning platform with Kubernetes. It is convenient to call the underlying interface.
The architecture of the entire platform was presented in diagram above. Outside the platform, there are Hadoop File System (HDFS), ElasticSearch (ES), high-availability distributed storage, etc. Both HDFS and ES are important data sources for the distributed TensorFlow platform, and these external data can be used on the PaaS platform only by opening up the network between each cluster and the Kubernetes cluster. The highly available distributed storage is the private storage provided by the PaaS platform to platform users. Its main function is to enable users to upload TensorFlow program codes, import and export TensorFlow models, and store training logs. Here, the implementation of Storage adopts GlusterFS is a high-performance and reliable storage system, an open source file storage system with good scalability and excellent storage capacity, and Kubernetes has good compatibility with it.
Platform Ecology
GlusterFS can centralize the idle storage space at the bottom layer to provide storage services in a unified manner, which improves the utilization rate of storage resources, and can manage these storage resources through the TCP network protocol.
Kubernetes is better compatible with GlusterFS. Heketi is a GlusterFS volume management framework based on RESTful API. Because Heketi itself provides a Rest-style API, Kubernetes can easily call this service, even in different GlusterFS clusters.
It will evenly distribute storage copies to different GlusterFS storage clusters, improving storage efficiency. availability. Compared with NFS [13], GlusterFS is more stable in container solutions, and NFS often has problems that cannot be mounted in Kubernetes, and this problem is also one of the hotly discussed topics in the community. After practice, GlusterFS was finally selected among the two solutions of GlusterFS and NFS.
It is very necessary to formulate a standard for the platform. If you do not do this, you will not be able to control the user’s behavior, and you will not be able to locate the user’s code path. This will cause exceptions to the modules imported by many users, which also violates the original intention of the platform design. In order to prevent users from building a new image every time they submit code and reduce the cost of maintaining the image, the platform needs to formulate corresponding specifications to implement TensorFlow applications in an overall framework. In this way, although the code will impose certain restrictions on the user, the implementation logic of the overall code has not changed, but it is subdivided into modules in several frameworks to facilitate the unified management of the platform. That is to say, the TensorFlow image of the platform is Built based on different versions of TensorFlow, these different versions of images can meet the needs of users to code on different TensorFlow versions, and are applicable to all users of the platform training.
Design and Implementation of API Platform
Currently the most popular TensorFlow programming language is Python. It is very simple to use Python to implement a TensorFlow application. For this, the platform provides a unified Python entry. Some system FLAGs will be defined in this base class of the platform, but the system FLAGs will be more complicated. This is done to avoid conflicts with user-defined FLAGs.
In Mind, these data include the start training time, current training time, current step count, total step count, and current status. API will dynamically calculate the expected completion time of the task based on the received data, and calculate the current running time. Percentage, the front-end Web service can display this information to the user in a friendly manner. For the user, the user’s code only needs to inherit the base class provided by the platform. There will be some basic operating parameters, such as training step size, whether to use GPU, synchronous or asynchronous mode, log storage directory, and model checkpoints. time etc. When rewriting the code, users only need to rewrite the three basic modules of model building (build_model), model training (train), model prediction or other post-training work (after_train), and the rest will be completed by the platform, and users do not need to care.
Model hosting is implemented based on TensorFlow Serving, which is also an open source project led by Google. Ultimately, the trained model is provided as a service in the form of gRPC. This is also a way of TensorFlow Model Serving, which can reduce the entire R&D effort. It supports the Serving function of multiple models, not limited to the TensorFlow model, users can also export the model and build their own model service according to their business needs.
Model Hosting
Model developers build models through TensorFlow, and obtain models after layer-by-layer neural network training. After verification, the training model will be released to Kubernetes for model hosting, that is, through TensorFlow Serving, users only need to write their own client, and call the model service through gRPC to obtain corresponding results.
The entire Serving work will also provide model services to users through the Kubernetes PaaS platform in the form of containers. The containerization process is as follows: use Ubuntu16.04 as the base image, install the necessary environment, and include Bazel, python, compiler The required dependent packages, etc., need to go to the external network to pull some dependent packages during the construction process. When building model services for users, it is also necessary to package the user-trained models into mirrors, and finally create Serving services with Kubernetes to provide users with gRPC services.
API Service
API will eventually be containerized and deployed on the Kubernetes platform to provide users with a Web management interface. All data is provided through API services. Create your own private storage; upload the written TensorFlow code, select some environment parameters, such as CPU, GPU, memory, log path, code path, custom FLAG, etc.; finally create a task. After the model training is over, you can also choose TensorFlow Serving (model hosting) service. The platform will provide a dedicated platform IP for each model service. Users only need to write their own client to call through gRPC.